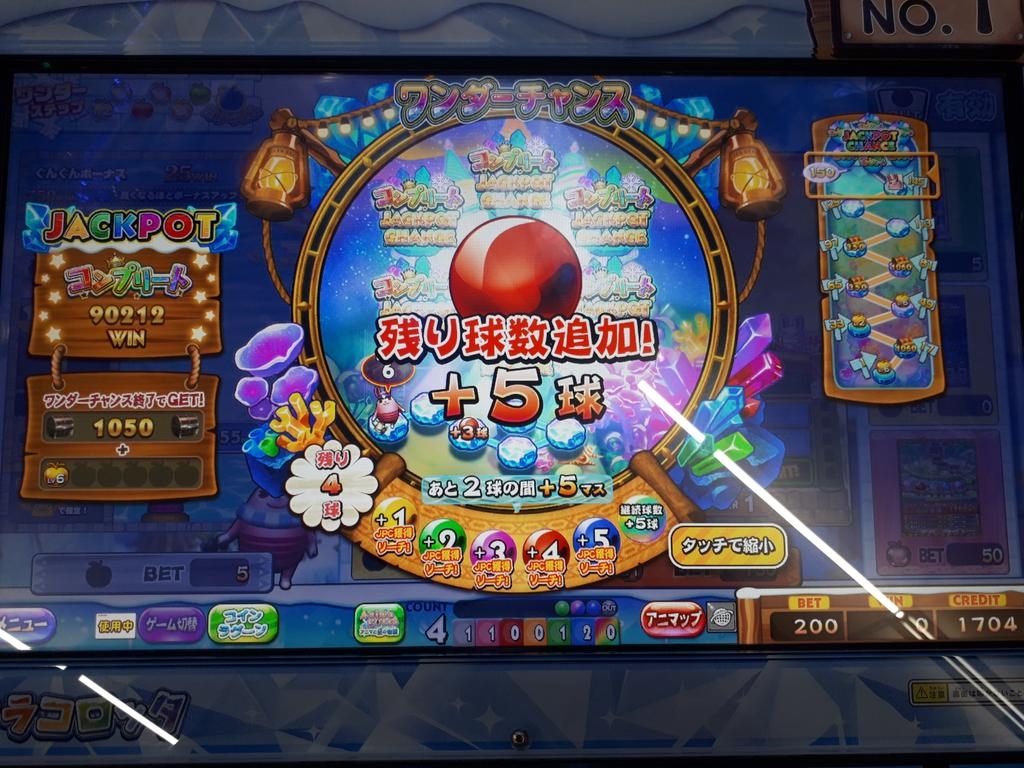
大卒向けということもあり、全体的に難易度は高め。
高卒でも解けないことはないが、問題文が長いものが多く、40問とはいえ、制限時間内に全て取り組むのはかなり難しい。
また、判断推理を中心に、どれくらい時間がかかりそうなのか見立てが難しい問題も多く、自分も100分の制限時間と勘違いして解いたら25点しか取れず、40分追加しても32点に留まった。
ただし、判断推理に関しては、難しいが良問が多く、試験ということを置いておけば割と楽しめる。逆に、文章理解は選択肢が際どいものが多く(そう言い切れるか?というものが複数ある)、やや悪問。
また、池上的な時事問題の割合が高く、警視庁のごとくガッツリ出る。社会や世界の動きに興味関心がないと、かなり厳しい。逆に経済の出題が一問もないのはかなり珍しい。
今年度は10人の募集のところに857人(女性は246人)も申し込んでおり、激戦となた。
データ
全40題 時間は2時間20分(140分)
試験問題持ち帰り可能。
星の数は難易度。
☆:易しい。小中学生レベル。
☆☆:普通。高校生レベル。
☆☆☆:難しい。大学入試~大学生レベル。
※:判定不能。悪問や、出題ミスなど。
文章理解
現代文に限って言えば、文章の量は多いものの、内容はどれも決して難しくはなく、むしろ読みやすい。
しかし、選択肢の記述が微妙で、かなり悩む。内容と食い違いがある、どう考えてもおかしい選択肢を消去していき、残ったもので妥当なものを選んでいくしかない。
ちなみに、公務員試験の現代文の文章理解で初めて間違ってしまった。くやしい。
1.現代文☆☆
内容把握。
ジャンルは科学技術で、はやぶさ2のミッションを例にして、制約への挑戦と未知への挑戦を論じ、現実的に様々な制約がある中、妥協(ディスカウント)せずに、未知への挑戦を最高の形で成し遂げられたと評価している。
そして、そんなことはなかなかないと言っているので④が正解。
2.現代文☆☆
内容把握。
俳句などの江戸時代に発達した言葉芸術は、人間が本来持つ野心や欲望、競争心や敵愾心を、うまく解消する(外から内へ、大から小へ)という内容。
これは、当時の日本が鎖国していたことで、フラストレーションを外国に向けられなかったからだと論じており、俳句の国際的普及はフロンティアが消滅した現代において、サスティナブルな余暇活動として大きな意義があると、著者は論じている。
サラッと読むとわりと納得してしまうが、冷静に考えると結構こじつけな気もする。江戸しぐさ的な。
正解は②
3.現代文☆☆☆
内容把握。
ものごとを理解するには「分ける」「つかむ」「さとる」3つの方法があるという内容。文章自体は面白く非常に読みやすいが、選択肢がわりとへたくそで、④と⑤でかなり悩む(どっちも文中で述べている)。正解は④らしいが、やはり⑤も内容に合致していると思う。
本文:分析的な研究手法の結果→科学技術の急速な進歩→公害問題
選択肢⑤:分析的な研究手法の結果→公害問題
微妙・・・!
4.現代文☆☆
内容把握。
社会プログラムをどう評価すべきかといった内容。なりとメタ的な考え方をする分野の話なので、少し読解に頭を使う。ただし、こちらは選択肢が選びやすい。
そして、内容や主張がN0.1のはやぶさ2の文章と割とかぶっている。正解は⑤
5.現代文☆
空欄補充。
「まれびと」をめぐって柳田國男と議論した折口信夫についての文章。倫理で折口の主張を知っていればあっさり解けるし、知らなくてもざっと内容を読めば簡単に選べる。
まれびと(来訪神)の訪問(ボケ)と、土地の精霊の対話(ツッコミ)から生まれた〈もどき〉が、日本文化生成発展のダイナミズムを生み出したという内容。
なので、外からやってくる未知の文化を翻訳し、独自に解釈し国風化するという①が正解。
6.現代文☆☆
文章整序。
時間の相対性についての文章。本文と関係ないけど、相対性理論をわかりやすく説明してくれと言われたアインシュタインは、「美人とデートしていると時間がすぐに経ってしまうのと一緒」と言ったらしい。
A:けれども、それ(共通な時間の尺度の導入)は私たちの都合による。
の次に
E:たとえば、人間が鉄砲玉のように早く歩けるとしよう。すると、秒刻みの時計の文字盤はおおざっぱすぎることになるだろう。(→時間を測る尺度として、その時計は使えない)
が来ることに気づくことが出来れば、A→Eとなっている選択肢が③しかないので、すぐに解けるはず。
7.英文
内容把握。
ツタンカーメン王墓の隠し部屋につていの文章。3つの異なるレーダー調査のデータを精査した結果、隠し部屋はなかったらしい。正解は⑤
8.英文
内容把握。
NASAの外惑星探査についての文章。英語が読めなくても、探査機パイオニアに、地球や人類について書かれた鉄板がついていることを知っていれば、選べてしまう。
ちなみに、このアイディアの発案者は、カール・セーガン博士。
正解は⑤
9.英文
内容把握。
セルフトーク(自分語り)は最初は委縮してネガティブな内容になりがちだが、練習によってポジティブなセルフトークができるようになるという内容。
選択肢が、どれもある程度は本文に合致していて、選びにくい。
正解は③
10.英文
文章整序。
カルヴィン・コフィというアイルランドの医学者が、腸間膜は複数の独立した構造のまとまりではなく、レオナルド・ダ・ヴィンチがスケッチした通り、ひとまとまりの器官であることを発見したという内容。医学的な単語がめちゃくちゃ難しい。
正解は②
11.英文
適語補充。
コロナやインフルエンザなどの感染症についての内容なのはわかるが、医学2連荘でかなり厳しい。というか、英語多い。正解は①
判断推理
ひねった問題が多く、なかり時間を食う。わずか40問で2時間20分の理由はここにある。
かと思えば、図形の問題は信じられないくらい簡単で、翻弄される。
12.集合☆☆
スマートウォッチ、AIスピーカー、パソコン、携帯電話の所持状況の集合問題。
・スマートウォッチとAIスピーカーのどちらか、もしくは両方を持っている生徒は必ずパソコンを持っている。
・パソコンを持っている生徒は必ず携帯電話を持っている。
・1機種のみ所有、2機種所有、3機種所有、4機種すべて所有の人数は等しい。
・携帯電話の所有者は100人。
・携帯電話を所有していない生徒は10人で、AIスピーカーを所有していない生徒は80人。
では、パソコンを所持しているが、スマートウォッチを所持していない生徒の数は何人かという問題。
初見ではなぜかできなかったが、あらためて解きなおしたらあっさり解けた問題。
AIスピーカーを所有していない80人の中に、携帯電話を所有していない10人が含まれるのに注意。
ベン図は以下のようになる。
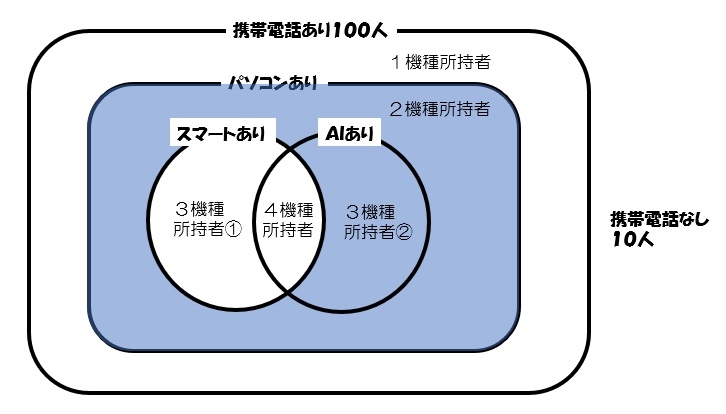
したがって
1機種所持者+2機種所持者+3機種所持者+4機種所持者=携帯所持者100人
になるので100÷4=各25人。
AIなしが80人で、携帯なしの10人を引くと70人。
よって
1機種所持者+2機種所持者+3機種所持者①=AIなし
なので、25人+25人+?人=70人
よって3機種所持者①は20人。
さらに3機種所持者②は5人。
パソコンを持っていてスマートウォッチを持っていないエリアは、図の色のついた部分なので、答えは25+5で、④30人。
13.整数☆☆
上下逆さにしても数字として読めるのは、0,1,2,3,5,8の6つ。
※6と9は回転させないと読めない(線対称ではない)のでダメ。
よって、100~999までの3桁の数で、百の位の数が、十の位、一の位の数字よりも大きいのは・・・
800、801、802、803、804、805の5個と
810~815の5個、820~825の5個、830~835の5個、850~855の5個で、800番台は5×5=25個
同様に、500番台は
500番台で4個、510番台で4個、520番台で4個、530番台で4個なので
4×4=16個
300番台は
300番台で3個、310番台で3個、320番台で3個なので
3×3=9個
200番台は
2×2=4個
100番台は1個なので、すべて足すと、25+16+9+4+1=55個
③が正解。
14.位置☆☆
パーキングエリアに入る前とパーキングエリアから出た後の座席の並びで考えられるのは、それぞれ3通りと2通りになる。

そして、2人だけ席が変わらなかったので・・・
①→④ 5人も席が変わっているのでダメ。
①→⑤ OK
②→④ 全員席が変わっているのでダメ
②→⑤ OK
③→④ OK
③→⑤ 全員席が変わっているのでダメ
よって正解は⑤休憩前も後も同じ席に座っていた2人のうちの1人はFさん。
考えられる組み合わせが多いため、ちょっとめんどくさい。
15.勝敗☆☆☆
この試験で最も難しかった問題。まず、問題文が長い。
A~Dの4人の園児が、ひらがな1文字の書かれたカードを3枚ずつ持っており、それはAは「た」「ぬ」「き」、Bは「ね」「ず」「み」、Cは「き」「つ」「ね」、Dは「こ」「あ」「ら」であった。この状態から以下のゲームを行った。
ルール
・4人は2組のペアを作ってじゃんけんをする。
・じゃんけんで勝った園児が負けた園児からカードを1枚受け取る。
・じゃんけんであいこの場合は、勝負が決まるまでじゃんけんを繰り返す。
・両方のペアの勝負が決まったら、1回戦終了とする。
・2回戦以降は、連続して同じ相手とならないようにペアを変えて行う。
・手持ちのカードが0枚の状況でジャンケンに負けた園児が出たらゲームを終了する。
これを4回戦まで終えた時の状況が次のとおりであるとき、確実に言えることとして最も妥当なのはどれか。
1.Aは3勝1敗で、現在5枚のカードを持っている。そのうち1枚は「ら」である。
2.Bは3勝1敗で、現在5枚のカードを持っている。そのうち1枚は「こ」である。
3.Cは1勝3敗で、現在1枚のカードを持っている。2回戦で負けて「つ」のカードを渡し、4回戦で勝って「た」のカードを受け取った。
4.「た」のカードを持っている園児は、A→D→B→Cの順番に変わった。
プレイヤーが4人しかいないため、Dの勝敗は1勝3敗。
ヒントの3と4より、「た」のカードのやりとりは2~4回戦で起きたことが分かる。
よって「た」のカードのやりとりは・・・
2回戦:×A→D〇
3回戦:〇B←D×
4回戦:×B→C〇
と判るので・・・
対戦カードは
2回戦:A対D B対C
3回戦:B対D A対C
4回戦:B対C A対D
と判る。
これと、A~Dの勝敗数を踏まえて総当たり表を作ると、A対Bは不可能なことが分かる(AとBが戦ってしまうと、どちらも3勝1敗にならないため)。
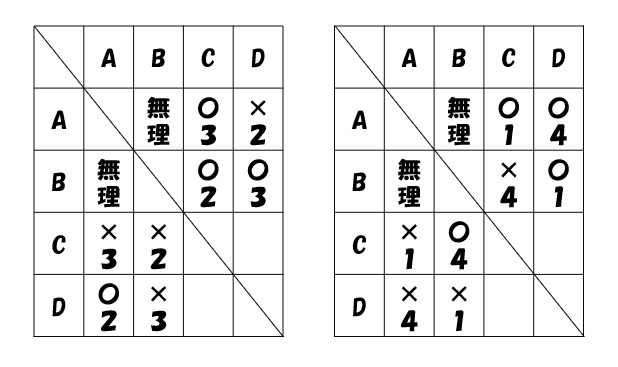
※数字は何回戦に行われたかを表しています。
よって正解は②Bが「こ」のカードを受け取ったのは1回戦。
B対Dの2回戦目は「た」をやり取りしているため。
これは、かなり難しく、かつ、いい問題。解けた時かなりスッキリしました。
16.順序☆
これは割とベタな問題。苦手な人多いけど。
生徒Xが折り返し地点までにすれ違った人数が9人ということは、折り返し地点でのXの順位は10位。
復路で4人に追い抜かれたため、順位は14位に転落。
しかし、ゴール目前で2人追い抜いたため、最終的な順位は、①の12位。
17.操作☆☆
操作のルール説明がめちゃくちゃ長く、丸々1ページも使っており、読む前に萎えるが、ルールが理解さえできれば、実はかなり簡単な問題。
1回目の操作も2回目の操作も、カードの裏表、コマの位置、色のいずれかが変化しているので、そのいずれも変化しない、「カードが裏でコマの色が黒の時の操作」は絶対にないことが分かる。※4つの操作に番号をつけると理解しやすい。
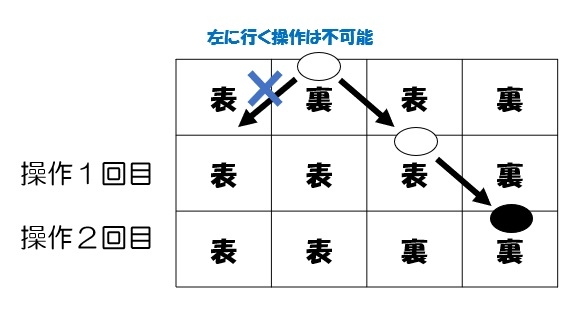
正解は④
18.平面構成☆
たった4ピースしかないジグソーパズル。ここにきて突然えらく易しい問題が出てくる(適性検査の図形問題っぽい)。ここは確実に点を取りたい。正解は③
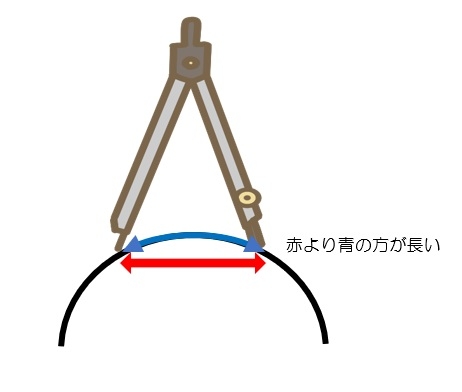
19.立体図形☆
曲面にコンパスで上手に円が書けるかどうかは置いておいて、曲線は直線に比べて距離が長いので(曲線を直線に戻すと判りやすい)、楕円が描ける。正解は⑤
数的推理
高校受験に毛が生えた方程式の文章問題が多い。
20.増加率☆☆
シチュエーションが資産運用で時代を感じる。
SDGsが推進するマイクロファイナンスって、貧困層への賭博って感じがするけど。
株式投資
1年後に元金が25万円増加するか、15万円減少するかのいずれか。
債券投資
1年後に元金の10%の利子が確実につく。
この場合、株式投資により元金が増加する確率がいくつ以上なら、債券投資の期待値を上回るか。ちなみに、Aさんの元金は100万円。
株式投資で25万円増加する確率をχ%とすると、以下の不等式が作れる。
25万×χ%+{-15万×(100-χ)%}>10万
1%は0.01なので
25×0.01χ+{-15(1-0.01)χ}>10
0.25χ-15+0.15χ>10
0.4χ>25
χ>62.5
正解は①の62.5%
21.連立不等式☆☆
若干難しかった。
屋外のヤギの頭数:χ頭
屋外のヒツジの頭数:5χ頭
屋内のヤギの頭数:y頭
屋内のヒツジの頭数:y/4頭
屋外と屋内のヤギとヒツジを合流させると、ヒツジの頭数がヤギの頭数の4倍になるため
4(外ヤギ+内ヤギ)=外ヒツジ+内ヒツジ
4χ+4y=5χ+y/4
χ=15y/4
外ヤギ(χ頭)を15y/4頭とすると
外ヒツジはその5倍なので75y/4頭になる。
よって外のヤギとヒツジの合計は90y/4頭。
これが1000頭未満と言っているので
90y/4<1000
y<44.4
内外すべての家畜の頭数はyでそろえると
(75+1+15+4)y/4頭
これが1000頭以上なので
95y/4>1000
95y>4000
y>42.1
屋内のヤギの頭数は
42.1<y<44.4
この1/4が屋内のヒツジなので
10.525<χ<11.1
正解は②の11頭
22.商とあまり
2022以下の自然数のうち、4で割ると3あまり、かつ、11で割ると5あまる数は何個あるか。
逆に考えると、4かけてから3足される数と、11かけてから5足される数なので
A:7,11,15,19,23,27,・・・
B:16,27,38,49,60,71,・・・
という二つの数列ができる。
すると、27はどちらの数列も持っているので、27の倍数で攻める。
ただし、数列Bは27×2=54は持っていないため、次は27×3=71となる。
つまり、数列Bで27の倍数が出てくるのは4回に1回。
B:16,27,38,49,60,71,・・・
数列Bは11ずつ増えていくので、2022までには、2022÷11≒183項ある。
この4項に1項は27の倍数なので、183÷4≒45.9
ただし、27が4項目ではなく2項目に来ているので、2項前にずれる。
よって、183+2=185項
185÷4=46.25
正解は③の46個
23.規則性☆☆
アニマロッタのハニーエイトみたいなハニカム構造の規則性。
中央の30は合計に含めないというところを読み飛ばしていて、愚かにも長考してしまいました。
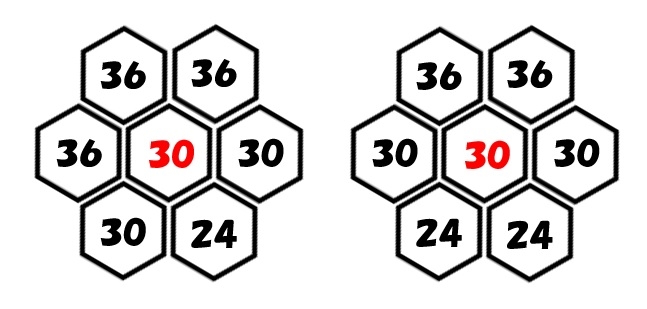
左のパターンなら、周囲の数の合計は192
右のパターンなら、周囲の数の合計は180
よって正解は④
24.連立方程式☆☆
やや問題文を読むのがめんどう。
予約サイト
電車賃(往復乗車券)が1割引きになるが、社員1人ごとに月会費がかかる。
電車を月に1回でも使ったら、月会費は発生する。
A:社員3人 出張回数の合計8回
予約サイトの方が、普通に駅で買うよりも180円高くなった。
B:社員5人 出張回数の合計20回
予約サイトの方が、普通に駅で買うよりも300円安くなった。
よって下のような連立方程式が立つ。
※駅の窓口の金額をχ円、予約サイトの月会費をy円とする。
8χ+180=7.2χ+3y
20χ-300=18χ+5y
これを解くと、予約サイトの月会費yは300円だと判る。
また、駅の窓口での金額χは900円であることも判る。
これを踏まえて、社員4人が出張する月において、予約サイトの方が駅の窓口よりも安くなるのに必要な最低出張回数zは・・・
※左辺を秋の窓口、右辺を予約サイトとする。
900z>810z+(300×4)
90z>1200
z>13.333・・・
よって正解は②14回
資料解釈
すべてめんどうくさい。難しいというより、検証にすごく手間がかかる。
総じて電卓持ち込み可でもいいと思う。
25.表☆☆
3桁の割り算を安全で速くできる人は有利。
正解は④で、製材用材と合板用材の合計の自給率は、18年に4割を超えている。
総需要の概算が36、国内生産の概算が17
26.グラフ☆☆☆
2019年1~12月の食中毒の対月増減のグラフ。
具体的なデータが12月しか載っていないので、それより前の月のデータはすべて逆算しなければならず、超めんどくさい。
逆算する項目は、細菌、寄生虫、化学物質、自然毒。
正解は⑤の19年の自然毒の発生件数は50件を超えている。
逆算して50件を超えたら計算を打ち切ってよい。
27.収支図☆☆☆
地球の熱収支図みたいな矢印で、魚介類の生産・消費構造の変化を表したもの。
データ項目が多く、複雑で、めちゃくちゃ面倒くさい。
計算しやすい奴からとりかかると、②だけ生き残るので、消去法で選んでしまった方がいい。
時事問題
あの警視庁をしのぐ難易度で、かなりガッツリ出題される。
バラエティー化した民放の朝の情報番組ではまず太刀打ちできない。NHKの「おはよう日本」でも厳しい。BSに加入して、「プライムニュース」や「激論クロスファイア」の視聴が要求される。
28.日本の医療☆☆☆
①正しい。健康寿命とは、平均寿命から介護状態の期間を差し引いたもの。
②不妊治療の助成制度は20年からではなく、20年までもあったが、21年にその適用範囲が拡大された。22年には、すべての不妊治療が保険適用(70%オフ)になったことに伴い、特定不妊治療助成制度は廃止。
また、待機児童の数は18年以降3年連続で増加していない。
21年4月の段階で全国に5600人ほどで、17年の26000人に比べて大幅に減少。
③RSウィルスは新型コロナウィルスと逆で、成人よりも小児の方が重症化する。
④黒い雨訴訟は、長崎地裁ではなく、21年の広島高裁の判決で、原告全員が被爆者と認定、国の敗訴が確定した。
⑤電子処方箋システムは21年ではなく、23年1月に全国で運用開始予定。
お薬手帳的なデータをマイナンバーカードで記録するが、クレジットカードには紐づいていない。
29.近年の世界情勢☆☆☆
①21年のイスラエルの政権交代についての記述。右派政党リクードが大勝し新政権になったのではなく、リクードが下野し、極右と中道の連立政権ができた。これにより通算15年も首相を続けたネタニヤフ氏は退陣した。
②ガザ地区を実効支配しているイスラム武装組織はヒズボラではなくハマス。
ヒズボラはレバノンを中心に活動するテロ組織で、ハマスもヒズボラもイスラエルに対抗している。
③21年6月のイランの大統領選についての記述。ライーシー新大統領が誕生した。ハメネイ師はイランの最高指導者であり、ロウハニ師は前大統領。なんとなく、ハメネイ師のポジションは日本でいう天皇っぽいが、その存在は象徴ではなく強大で、大統領すら解任できる。
④21年のアフガニスタン戦争終結の記述。タリバンが政権に返り咲いた。正しい。
⑤20年のアゼルバイジャン(トルコが支援)・アルメニア(ロシアが支援)紛争についての記述。どちらもソ連から独立した国だが、係争地「ナゴルノ・カラバフ」を争ってなんと30年以上も戦っている。「カシミール地方」はインドとパキスタンの係争地。
30.近年の法改正☆☆
①21年の「教育職員等による児童生徒性暴力等の防止等に関する法律」についての記述。学生にわいせつ行為を行い教員免許を失効した人も3年たてば、再び教員免許の再授与が可能だったため、都道府県教育委員会は、「都道府県教育職員免許状再授与審査会」を開いて意見を聞かなければならなくなった。また、性暴力で免許を失効した人物のデータベース(過去40年分)は国が整備することになった。
②成人年齢引き下げについての記述。正しい。
22年度から18、19歳は少年法ではなく、刑法が適用されることになったが、罪が確定するまでは実名報道はされないといった手心が加えられた。
③20~21年の改正著作権法についての記述。
前半の記述は令和3年度の改正内容で、全国の図書館は絶版本などの入手困難な書籍の電子データを、条件を満たせば利用者に直接メール送信できるようになった(コロナ禍で直接図書館に足を運びにくくなったため)。
だが、令和2年度の改正では、ネットでの海賊版の対策をしたので、いくらクールジャパンでも、海外在住の外国人に、漫画本を含む新刊の電子データをメールで全ページ送信はしない。
④21年の改正国民投票法の記述。海外居住者にも国民投票は認められているので誤り。
⑤22年に施行された「改正地球温暖化対策推進法」についての記述。温室効果ガスの排出実質ゼロ(カーボンニュートラル)は40年までではなく50年までの達成目標とされている。また、日本では炭素税に当たる温暖化対策税が22年ではなく12年にすでに導入されている。
自然科学
警視庁と異なり、こちらはかなり易しい。
選択肢の記述がかなり難しそうに見えるが、よく読むと正解の記述だけ易しいので、知っている選択肢を選べば解ける。マニアックな選択肢は絶対に選んではいけない。
31.物理☆
波の性質。アルキメデスの原理は中学1年生で習う浮力についての原理なので、絶対に選んではいけない。※と言うかそれだけ知っていれば解ける。
波面とは、波の位相が共通しているところを連ねた面で、どの位相を選んでも波の進行方向と必ず垂直になる。
ホイヘンスの原理とは、波を点レベルにまで細かく分解すると球面波(平面では同心円状)になっているという原理。ここから回折現象が説明できる。
32.化学☆☆
まさかの有機化学。
①セルロースは多糖類で2糖(単糖2個で構成される糖)ではない。また、コラーゲンはタンパク質。
②デンプンには、水に溶けないアミロペクチンと、溶けやすいアミロースの2種類の成分がある。よって記述が逆。もち米はほとんどがアミロペクチン(弾力性あり)で構成されている。うるち米はアミロースが3割、アミロペクチンが7割ほど。
③ウラシルはRNAのみにありDNAにはない塩基。またDNAの情報をRNAに移すことは翻訳ではなく転写と言う。
④アミノ酸はアミノ基がどの位置の炭素にくっついているかでα、βと区別される。しかし、アミノ基とカルボキシ基が同一炭素原子にくっつくことはないので誤り。
ちなみに、人体のタンパク質を構成するアミノ酸はすべてα型。
また、ヨウ素デンプン反応はアミノ酸ではなく、デンプンのアミロースのスプリングの中にヨウ素分子が入ることで青紫色になる(アミロペクチンの場合は赤紫)。
⑤酵素に関する基礎的な記述。正しい。
33.生物☆
細胞小器官について。かなり基本的な問題。
①酸素を用いてATPを合成するのは核ではなくミトコンドリア。
②ミトコンドリアは核膜と直接つながっていない。グリコーゲンは細胞質基質にて酵素によって合成される。
③葉緑体についての記述。正しい。
④ゴルジ体(分泌)とリソソーム(分解)の記述が逆。リソソームってゴルジ体から作られるのは知らなかった。
⑤細胞膜は一重幕ではなく二重膜。
人文科学
地歴もやや易しいので、点数を稼ぎたい。
34.日本史☆
日本の文化について。通史的な問題。
①弘仁・貞観文化は奈良時代ではなく平安時代初期。隋ではなく唐の影響を昇華した。
②東山文化は室町時代後半の文化。落語や浮世絵は江戸時代に生まれた。千利休は戦国時代の人物。
③元禄文化は江戸ではなく畿内を中心とした上方文化。林羅山は幕府の御用朱子学者で江戸初期の人物。よって文化としては寛永文化となる。国学が大成されるのは江戸時代の後期。
④化政文化の記述。正しい。
⑤明治時代の美術についての記述。黒田清輝(洋画)と岡倉天心(日本画)が逆。白馬会はお堅い明治美術会から離脱する形で黒田清輝らが結成した自由な西洋画のグループ。
35.世界史☆☆
フランス革命についての記述。
①アンシャンレジームは、聖職者が第一身分。貴族が第二身分。それ以外(ブルジョワ含む)が第三身分だった。
②立法議会は、1791年憲法(立憲君主制と制限選挙を定めた)を発布して解散した国民議会に代わって召集。立憲君主制を目指すフイヤン派と、共和制(王制廃止)を目指すジロンド派が対立した。よって、フイヤン派とジロンド派が逆。ちなみに、立法議会は翌年には、国民公会に代わっているため、影が薄い。
③第一共和政後のロベスピエールの恐怖政治についての記述。正しい。
④ブリュメール18日のクーデターの記述。ナポレオンは、総裁政府を倒して、統領政府を樹立。総裁と統領が逆。
また、アミアンの和約でイギリスと休戦した後にナポは皇帝となったため、これを危険視したイギリスと再びバトルがスタート(有名なトラファルガーの海戦などはこの時)、イギリスに経済制裁をするためにナポが大陸封鎖令を出している。
⑤革命暦はフランス革命時に使われていた暦。ナポが台頭してくる前の1793年からすでに使っていた。
36.倫理☆☆
名前をそのまま入れ替えているのではなく、中途半端にほかの人物の記述を混ぜているので、少しいやらしい。
①ルターは贖宥状の販売をしたのではなく、それを批判した。
②デカルトのコギトエルゴスムの記述。正しい。
③実証主義はカントではなくコント。ここにきてギャグなのか。コントは社会学の父として有名な哲学者。実証主義は経験主義やプラグマティズムに近く、先験的だったり形而上学的な考察を一切排したという点で、カントの理性批判と大きく異なる。
④アダム=スミスではなく、マルクスの記述が中途半端に混ざっている。
⑤神は死んだと言ったのはニーチェだが、後半はハイデッガーの記述。
37.地理☆
世界の農業。中学生くらいの知識で解ける。
①中国の畑でキャッサバやヤムイモはあまり作らない(どっちかと言うと東南アジア)。
また、上海料理は海鮮が有名で、麻婆豆腐など辛いのは四川料理。
②ジャガイモは高温多湿な気候には適していない。棚田は山間部の斜面を利用して作られる田んぼで、沿岸部の干潟にはない。
③コートジボワールやガーナは小麦の世界有数の輸出国にはなっていない。
④レモン、オリーブ、ブドウなどの地中海性気候はアルプス山脈よりも南のエリア。
⑤アメリカの適地適作のついての記述。正しい。
社会科学
いずれも、かなり内容が深く、生半可な知識だと逆に混乱する。
38.政治☆☆☆
日本国憲法の自由権について。
①憲法に規定される思想・良心の自由は、私人間では直接適用できないとされている(三菱樹脂事件)。
②報道の自由は21条の表現の自由で普通に保障されている。
③日本国憲法では大学の自治は明文化されていない(ただし憲法23条を根拠に認められていると考えられている)。よって高校の自治もされていない。
④かなり微妙な選択肢。身体の自由として、令状主義、法廷手続きの保障などが明記されているが、国選弁護人制度は、被告人はともかく、被疑者については明文化されていない(被疑者国選弁護人制度は04年に導入、06年に実施)。
⑤正しい。経済活動の自由は精神の自由よりも、公共の福祉を理由とした制限が強くかけられている(ダブルスタンダード)。
39.政治☆☆☆
日本の司法制度について。
①量刑についても裁判官(抽選で選ばれた一般人)が関わるので、わりと負担が大きい。
②正しい。公の秩序、善良な風俗を害する恐れがある場合は、対審を非公開にできるが、政治犯罪必ず公開される。同じような内容が昨年度の警視庁でも出題された。
③違憲審査権は、もちろん下級裁判所にも認められている。
④検察審査会は検察が不起訴とした判断が妥当だったかをくじで選ばれた有権者11人が審査する制度。ここで2回続けて「起訴相当」とされた場合は、検察官ではなく、裁判所が指定した弁護士が、被疑者を強制起訴する。
⑤知的財産高等裁判所は東京高裁の支部。すべての高裁に設置はされていない。ちなみに、今年移転するらしい。
40.社会☆☆
冷戦後の国際情勢。やや簡単。
①南アフリカのアパルトヘイトについての記述。正しい。
②北アイルランドは現在もイギリスから独立していない。
③米国第一主義はオバマ大統領ではなく、トランプ大統領が掲げた。
④リーマンショック後もFTAの発効件数は増えている。※19年で320件。
⑤日本の製品輸入比率は今なお高い。